The Magic of Morphing Math: A Deep Dive into Normalizing Flows
generative-models · deep-learning · math · normalizing-flows
Normalizing flows make a very explicit trade:
- If you can build an invertible map with a tractable Jacobian,
- then density estimation becomes straightforward: exact likelihoods via change-of-variables.
That “if” is the entire game. Flow models are not “universal magic generative models”; they are generative models constrained by invertibility and compute. The payoff is that you don’t need a surrogate objective (like an adversarial loss): you can optimize log-likelihood directly and evaluate density exactly.
What you’ll get:
- The change-of-variables identity and where the Jacobian term comes from.
- Why “invertible + tractable Jacobian” is the real architectural constraint.
- How RealNVP-style coupling layers make the math computationally cheap.
The Core Philosophy: Simplicity to Complexity
The central idea is to model a complex data distribution by transforming a simple, well-defined base distribution (usually a standard multivariate Gaussian).
We define a deterministic and invertible function such that:
Because is invertible, we can also go backward: . This invertibility is the "secret sauce" that allows us to evaluate the density of our data exactly.
The Change of Variables Formula
To relate the density of our complex data to our simple latent space, we use the Change of Variables Formula. If is invertible and differentiable, the relationship between densities is:
Here, is the Jacobian of the inverse transformation. The determinant of the Jacobian accounts for how the transformation stretches or compresses the "volume" of space. If the function pulls points apart, the density decreases; if it pushes them together, the density increases.
Training via Log-Likelihood
In practice, we don't maximize the likelihood directly because multiplying thousands of small probabilities leads to numerical underflow. Instead, we use the Log-Likelihood:
In code, the training objective is usually implemented via the inverse pass (because you need anyway):
This is the clean theory→implementation bridge: map data to latent, score under the base density, and add the log-det correction.
Sign convention (the common confusion):
- If you compute in the forward direction, then .
- Training via the inverse is convenient because is required to evaluate .
Why the Logarithm?
- Numerical Stability: It turns products into sums, preventing our computers from rounding small values to zero.
- Easier Optimization: The logarithm is monotonic. Maximizing the log-likelihood is mathematically equivalent to maximizing the likelihood itself.
- Gradient Friendly: Sums are much easier to differentiate than products, making backpropagation significantly more efficient.
Building Deep Flows: The Power of Composition
A single simple transformation isn't enough to capture the nuance of a "Two-Moons" dataset, let alone an image. However, the composition of multiple invertible functions is itself invertible.
If we have layers:
The log-determinant of the total Jacobian is simply the sum of the log-determinants of each layer:
This additive property is a computational lifesaver. It allows us to stack simple layers to build a "deep" flow without the math becoming intractable.
Real NVP: The Architect's Choice
One of the most influential flow architectures is Real NVP (Real-valued Non-Volume Preserving). It uses Coupling Layers to ensure the Jacobian is easy to calculate while remaining highly expressive.
The Coupling Mechanism
RealNVP is often explained as “split the vector into two halves.” The implementation you actually write is usually the slightly more general version: masked coupling.
Let be a binary mask. Define:
- Identity Part: (stays the same).
- Transformed Part: .
The functions (scale) and (bias) can be any complex neural network. They don't need to be invertible themselves because we only ever evaluate them on the identity part .
In masked form, that same idea is: transform only the coordinates and leave the coordinates unchanged. Across layers, you alternate masks so every dimension gets transformed multiple times.
The Genius of the Jacobian:
Because doesn't depend on , and depends on only element-wise, the Jacobian matrix becomes lower triangular. The determinant of a triangular matrix is just the product of its diagonal elements.
Operationally, this is the real punchline: you never form the Jacobian. You just sum the relevant entries of :
That’s why coupling layers scale: the log-det is an reduction, not an matrix determinant.
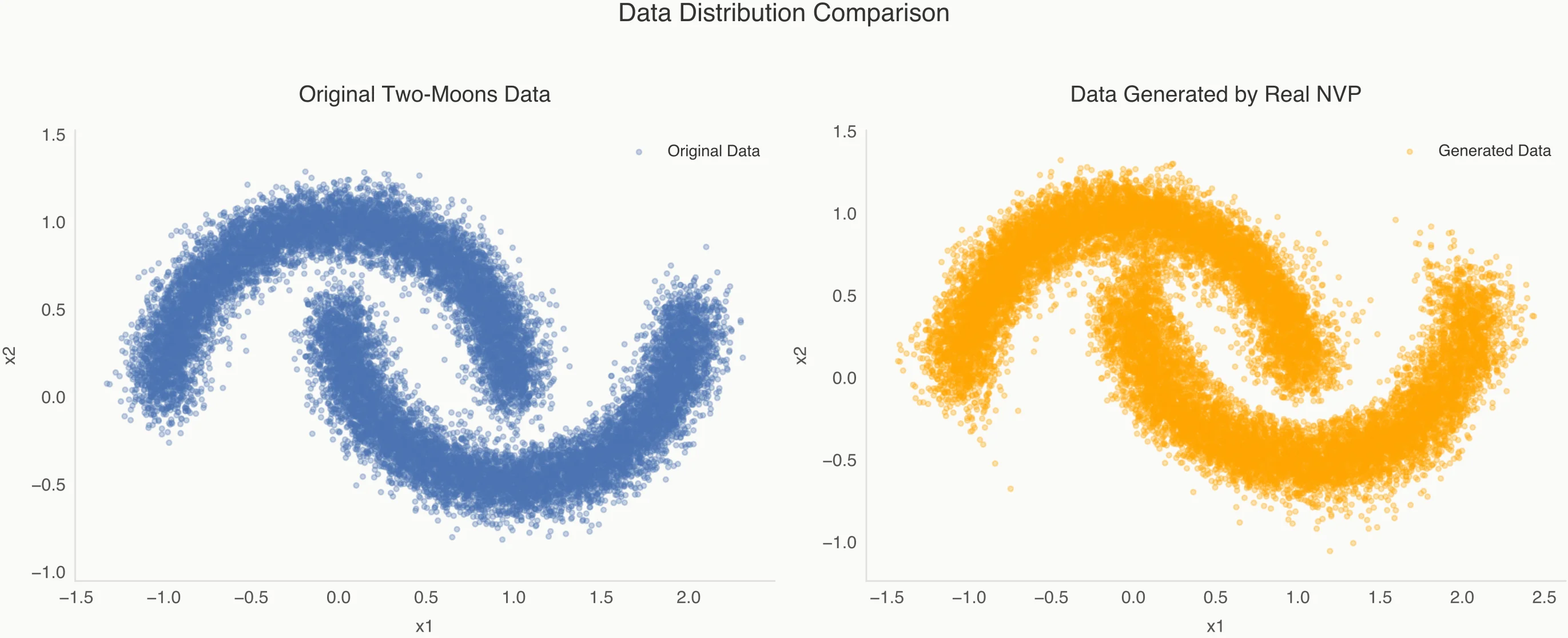
Seeing it in Action: The "Two-Moons" Experiment
To prove the power of this math, let's look at a Python implementation using PyTorch. We want to see if our model can learn to turn a circular Gaussian distribution into two interlocking crescents.
import torch
import torch.nn as nn
class CouplingLayer(nn.Module):
def __init__(self, data_dim, hidden_dim, mask):
super().__init__()
self.mask = mask
# Neural networks for scale and bias
self.s_net = nn.Sequential(nn.Linear(data_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, data_dim))
self.b_net = nn.Sequential(nn.Linear(data_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, data_dim))
def forward(self, z):
z_a = z * self.mask
s = self.s_net(z_a)
b = self.b_net(z_a)
x = z_a + (1 - self.mask) * (z * torch.exp(s) + b)
log_det_J = ((1 - self.mask) * s).sum(dim=1)
return x, log_det_J
def inverse(self, x):
x_a = x * self.mask
s = self.s_net(x_a)
b = self.b_net(x_a)
z = x_a + (1 - self.mask) * ((x - b) * torch.exp(-s))
log_det_J_inv = ((1 - self.mask) * -s).sum(dim=1)
return z, log_det_J_invPractical stability note: many RealNVP implementations bound the scale output to avoid exp(s) blow-ups (e.g., s = tanh(s) or s = clamp(s, -c, c)). For low-dimensional toy data you can often get away without it, but it’s worth calling out.
The Evolution of a Distribution
The beauty of Normalizing Flows is that we can "peek" inside the model to see how the data evolves through each layer. Initially, the points are clustered in a standard normal "blob" (). As they pass through successive layers, the space is stretched, folded, and shifted.

What to look for:
- Early layers mainly break symmetry and push mass into the right coarse geometry.
- Mid layers start to carve the gap between the crescents (the hard part).
- Late layers mostly sharpen boundaries rather than changing global structure.
Analysis of the Flow
- Layers 1-3: The model begins by breaking the symmetry of the Gaussian, pulling the distribution into an elongated shape.
- Layers 4-6: The "coupling" effect becomes visible as the model starts to "bend" the distribution, creating the hollow space between the two crescents.
- Layers 7-8: The final layers refine the boundaries and ensure the density perfectly matches the training data.
The Result: From Chaos to Order
After training for 1000 epochs, the transformation is mesmerizing. We start with a standard normal distribution in the latent space () and watch as each layer of the flow warps, stretches, and bends the space until it perfectly matches the "Two-Moons" data ().
- Training Loss: We observed the negative log-likelihood drop from initial noise to a stable point around ~1.01 (it typically plateaus after a few hundred epochs with small oscillations).
- Generation: To create new data, we simply sample from the Gaussian and run the "forward" pass. The model creates "moons" that are indistinguishable from the training set.
Minimal recipe (for 2D toys):
- Base distribution: standard Gaussian
- Depth: ~8 coupling layers is usually enough to carve the gap cleanly
- Capacity: hidden widths that are too small underfit (blurred / collapsed moons); too few layers can’t carve the separation
Conclusion
Normalizing Flows represent a beautiful intersection of rigorous mathematics and deep learning. By enforcing invertibility and tracking volume changes via the Jacobian, we gain the ability to evaluate exact probability densities—something Generative Adversarial Networks (GANs) simply cannot do.
Whether you are interested in physics-informed machine learning or high-fidelity image generation, "the flow" offers a mathematically grounded path forward.
If you want one takeaway: flows buy you exact likelihoods by paying the price of invertibility + Jacobian bookkeeping. Everything else is architecture to make that price affordable.